
How Tellen is Using AI and Large Language Models: RAGs to Riches
Introduction to Tellen and our use of AI Tellen builds audit quality solutions for accounting firms, taking advantage of the latest innovations in Large Language Models (LLMs) and Artificial Intelligence (AI). With private endpoints, a secure architecture, and an elegant user interface, Tellen provides a range of applications from chatbots trained on our customers’ own data all the way to those aiding audit compilation. To do this, we need to efficiently and effectively extract data from source documents—PDFs, Word documents, images, spreadsheets, as well as audio and video—but also use that source data to answer questions posed by us and the user. Those questions will often then be routed through LLMs.
However, LLMs come with limitations, including finite context windows, domain knowledge gaps, and “hallucinated” answers. We can work to counter that, by growing context windows, scraping more data and further training or fine tuning models. But LLMs will still always fundamentally lack full domain knowledge and the ability to efficiently get to the precise knowledge required for a task given their mathematical backbone.
So what do we do? One method of mitigating these issues is to augment queries with the information required to answer them—sourced from a more relevant and sourceable dataset than the LLM’s training data. For enterprises, this dataset is often proprietary firm (i.e., the firm’s procedural handbook for completing an audit) or client data (i.e., a client’s commercial lease contract) that was not made available to the LLM when it was initially trained, but that provides the specificity required to answer the user’s question more precisely. A user’s query and this new information is then sent to the LLM as a longer query, which is demonstrated to give far more accurate results. Not only that, the augmenting information is citable as sources for the given answer, taking away some of the black box nature of LLM responses.
R1.png
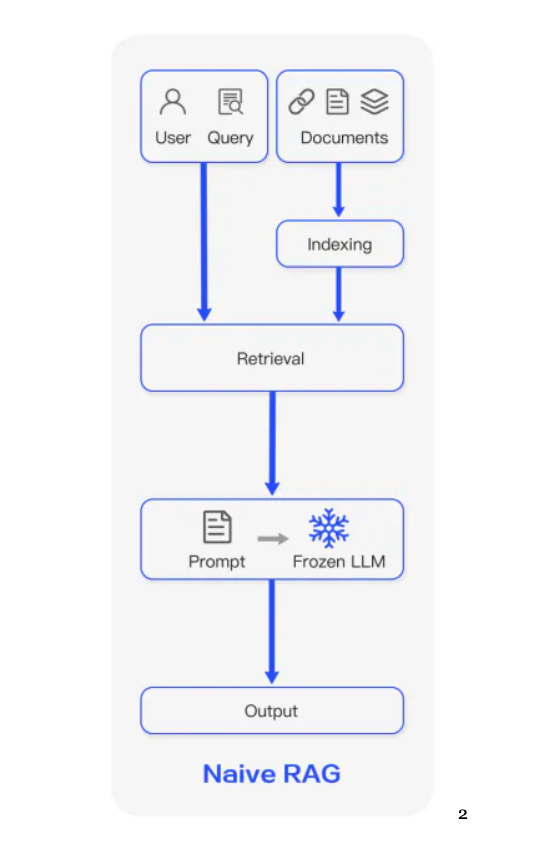
**RAG Phase 1: Rudimentary Semantic Search ** This is where Retrieval Augmented Generation (RAG) comes in. RAG is essentially the concept of retrieving better data to augment the contents of your LLM’s context window, and then generate a useful output.
Tellen began its journey just under a year ago with the most rudimentary form of RAG. We split input text into “chunks,” based solely upon the number of characters in them, and created high dimensional vectors, known as embeddings, to represent them. These were then stored in a database alongside the original chunk. When the user entered a query, the same embedding model was used to create a vector representing it. The distances between the query vector and each chunk’s vector was calculated (using cosine similarity or a similar distance metric), and so the “closest” information was retrieved. This is the information that was then entered together with the original query to the LLM. The search process is known as semantic search.
Where is Tellen right now with RAG? Tellen’s data sources are currently limited to text, tables, and images. (Any images will undergo OCR and so become text; audio or video sources will be transcribed and so converted to text. Multimodal LLMs, though, are a preferred option for these formats, as described below.) The data could come in the medium of long form prose, standardized documents such as 10Ks or W2s, a bank statement, a set of frequently asked questions, or a combination of these.
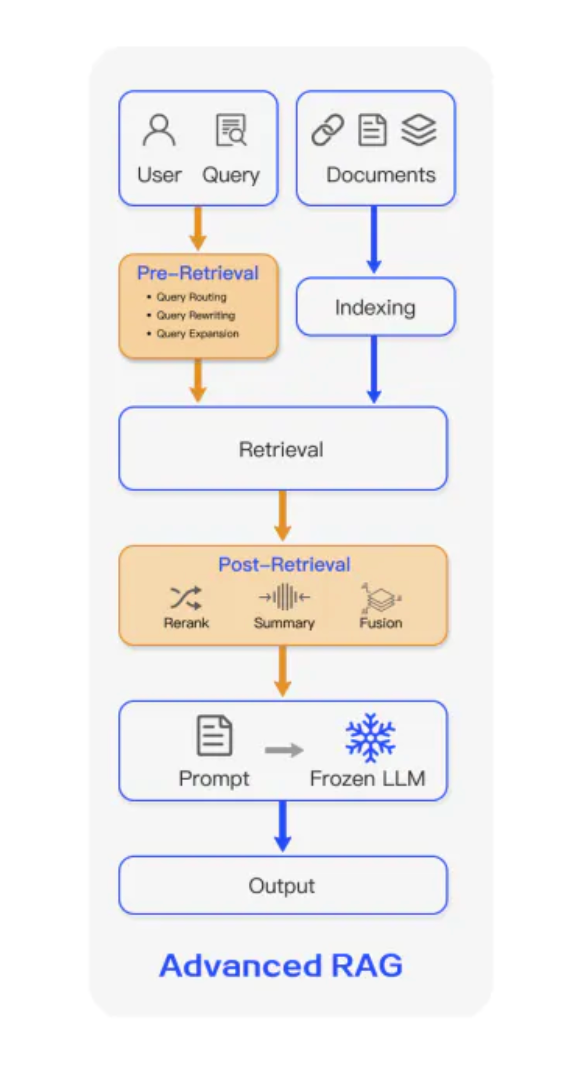
RAG Phase 2: Precision Chunking and MetaDocumenting Agents Tellen is more sophisticated now with its RAG methodology. We developed a technique that we call “Precision Chunking” to obtain our chunks not by simply counting characters, but rather by delineating paragraphs (and tables, etc.), as determined by Document Intelligence AI models. This prevents corrupting input data by splitting sentences, paragraphs or tables and, ultimately, aims to maintain minimal subject separation between chunks. We also store metadata alongside the chunks and vectors, most important of which for auditors is the bounding box of a PDF; this allows customers to see precisely the source of information, as well as surrounding context.
We then create vectors on those chunks using OpenAI’s Ada-2 embeddings model. If seeking answers across multiple documents, we use a technique that we call “MetaDocumenting,” which summarizes the documents entirely and applies the same embeddings model to that summary. On receiving a user query, we run a semantic search on those MetaDocuments (based on the given query) to choose the most relevant documents, and then run another semantic search over the chunks within those documents only. We then concatenate the original query with the received chunks and pass that to an LLM which will synthesize an output.
R2.png
The work discussed so far slots into the pre-retrieval and retrieval elements of the general diagram here. Pre- retrieval, we use Precision Chunking to better delineate between source data, and we use MetaDocumenting pre- and during retrieval to ensure we’re getting the most relevant data.
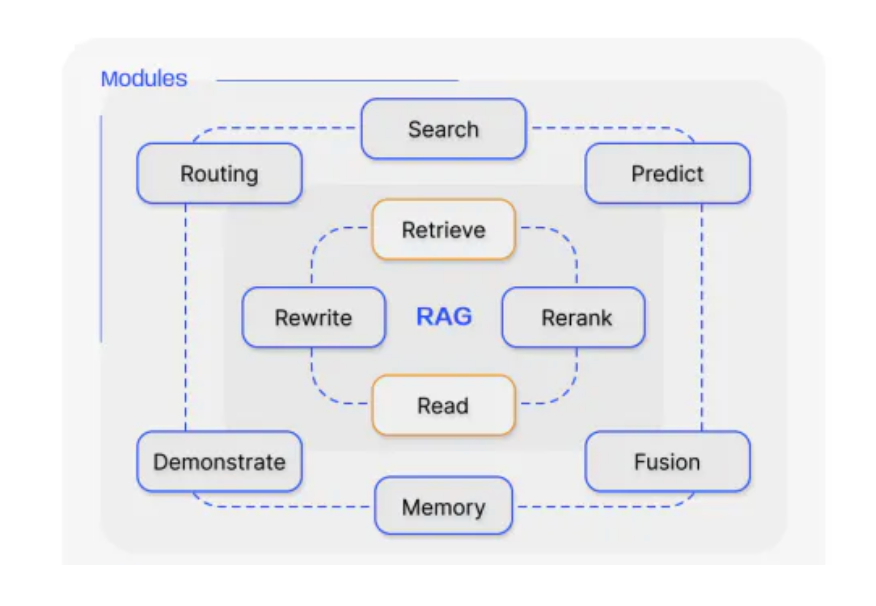
Where is Tellen going with RAG? RAG Phase 3: Agentic Workflows We’re pleased with our rapid progress, but what we really want is an advanced system of agents that can be stitched together into a workflow to optimize an answer. This would form a RAG pipeline together with multiple modules (or workflows), including more sophisticated routing, reranking, refined semantic search, etc. These modules will then be used in certain workflows depending on the type of query asked.
R3.png
Key Definitions Tellen users or Tellen itself on the backend will enter queries into a routing agent, which will consist of a set of actions constituting a path through various modules. The agent’s path can vary given the output of certain modules. The primary tools will be LLMs. Embedding models will be used to create multi-dimensional vectors, also known as embeddings, of input data such as paragraphs or tables; this process is known as indexing. Some agentic workflows will be scripted entirely by Tellen, parsing, for example, an audit file to deal with certain information; others will be driven by chatbots. Those driven by chatbots may route users’ queries to modules more appropriate to a particular task.
In the next post in this series, we’ll dive into precisely what modules we’ll be building.
Notes:
1 Though in common parlance, the word “hallucination” is a bad choice given that, with its statistical backbone, all LLM output is hallucinated. Some hallucinations can be more accurate than others and those below a certain threshold of accuracy are termed hallucinations.